
美国之行(下篇):圣地亚哥
受邀参加在 San Diego 举办的 Go Contributor Summit 2023 期间的所见所闻,和各路大神的交流心得,以及在 San Diego 的旅行记录。
Live fast. Die young. Be wild. Have fun.





受邀参加在 San Diego 举办的 Go Contributor Summit 2023 期间的所见所闻,和各路大神的交流心得,以及在 San Diego 的旅行记录。

相信那些曾经使用 Go 写过 proxy server 的同学应该对 io.Copy()/io.CopyN()/io.CopyBuffer()/io.ReaderFrom 等接口和方法不陌生,它们是使用 Go 操作各类 I/O 进行数据传输经常需要使用到的 API,其中基于 TCP 协议的 socket 在使用上述接口和方法进行数据传输时利用到了 Linux 的零拷贝技术 sendfile 和 splice。 我前段时间为 Go 语言内部的 Linux splice 零拷贝技术做了一点优化:为 splice 实现了一个 pipe pool,复用管道,减少频繁创建和销毁 pipe buffers 所带来的系统开销,理论上来说能够大幅提升 Go 的 io 标准库中基于 splice 零拷贝实现的 API 的性能。因此,我想从这个优化工作出发,分享一些我个人对多线程编程中的一些不成熟的优化思路。
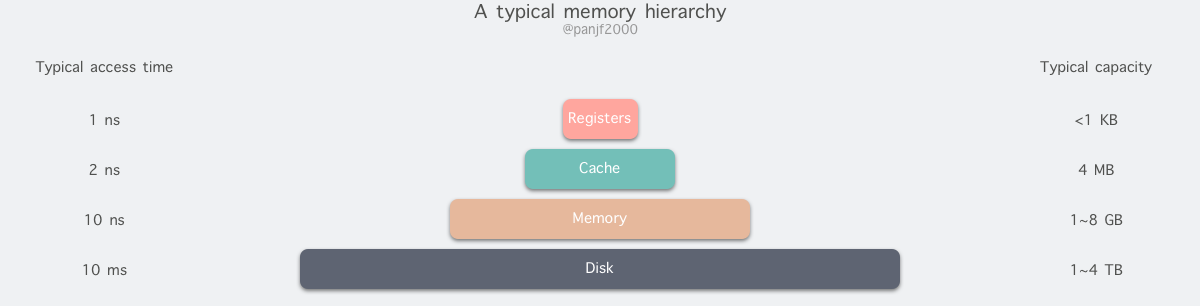
虚拟内存是当今计算机系统中最重要的抽象概念之一,它的提出是为了更加有效地管理内存并且降低内存出错的概率。虚拟内存影响着计算机的方方面面,包括硬件设计、文件系统、共享对象和进程/线程调度等等,每一个致力于编写高效且出错概率低的程序的程序员都应该深入学习虚拟内存。 本文全面而深入地剖析了虚拟内存的工作原理,帮助读者快速而深刻地理解这个重要的概念。
在目前的技术选型中,Redis 俨然已经成为了系统高性能缓存方案的事实标准,因此现在 Redis 也成为了后端开发的基本技能树之一,Redis 的底层原理也顺理成章地成为了必须学习的知识。 Redis 从本质上来讲是一个网络服务器,而对于一个网络服务器来说,网络模型是它的精华,搞懂了一个网络服务器的网络模型,你也就搞懂了它的本质。 本文通过层层递进的方式,介绍了 Redis 网络模型的版本变更里程,剖析了其从单线程进化到多线程的工作原理,此外,还一并分析并解答了 Redis 的网络模型的很多抉择背后的思考,帮助读者能更深刻地理解 Redis 网络模型的设计。
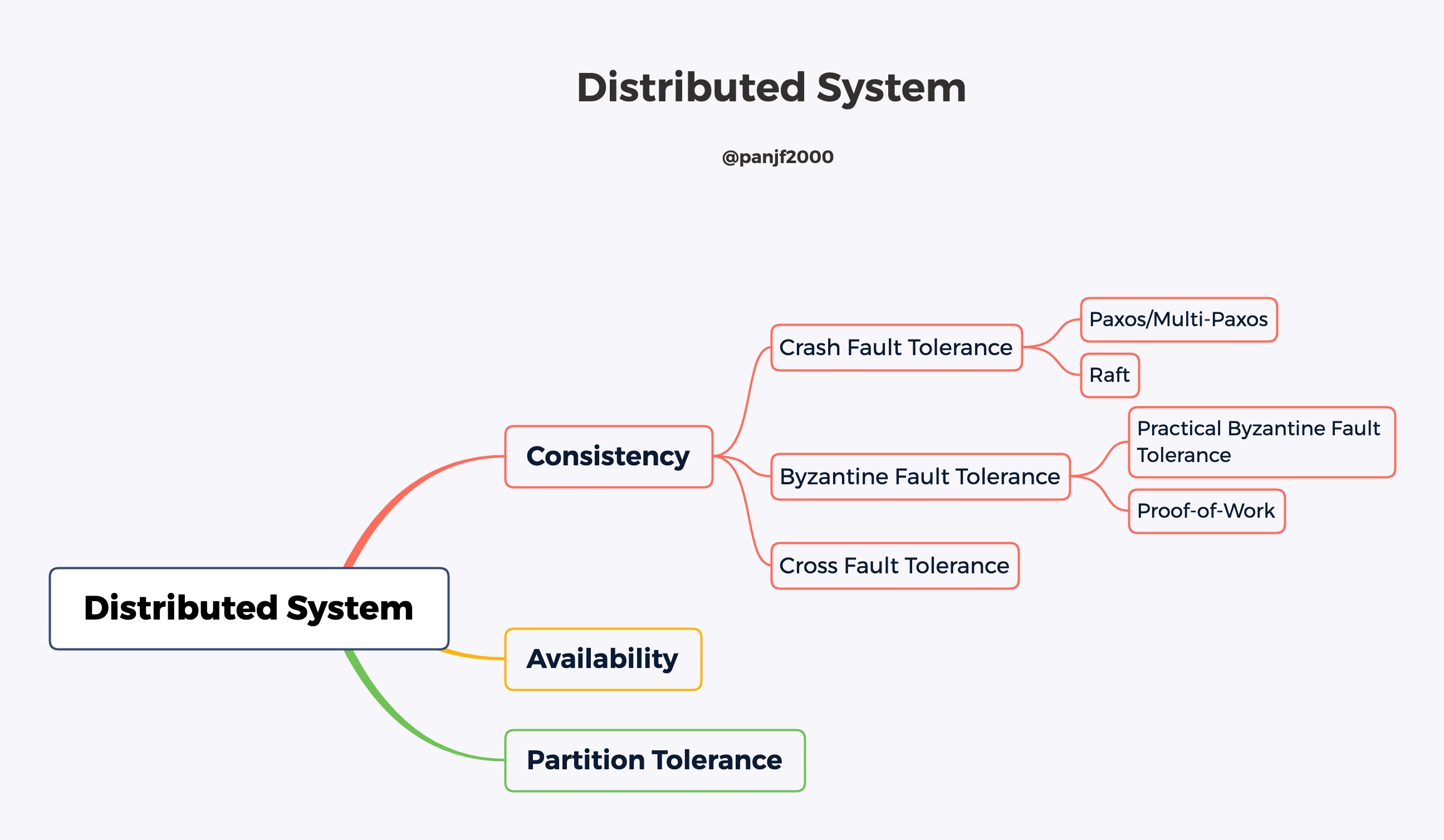
分布式事务是分布式系统必不可少组成部分,基本上只要实现一个分布式系统就逃不开对分布式事务的支持。本文从分布式事务这个概念切入,尝试对分布式事务最核心的底层原理进行逐一的剖析,内容包括但不限于 BASE 原则、两阶段原子提交协议、三阶段原子提交协议、Paxos/Multi-Paxos 分布式共识算法的原理与证明、Raft 分布式共识算法和分布式事务的并发控制等内容。
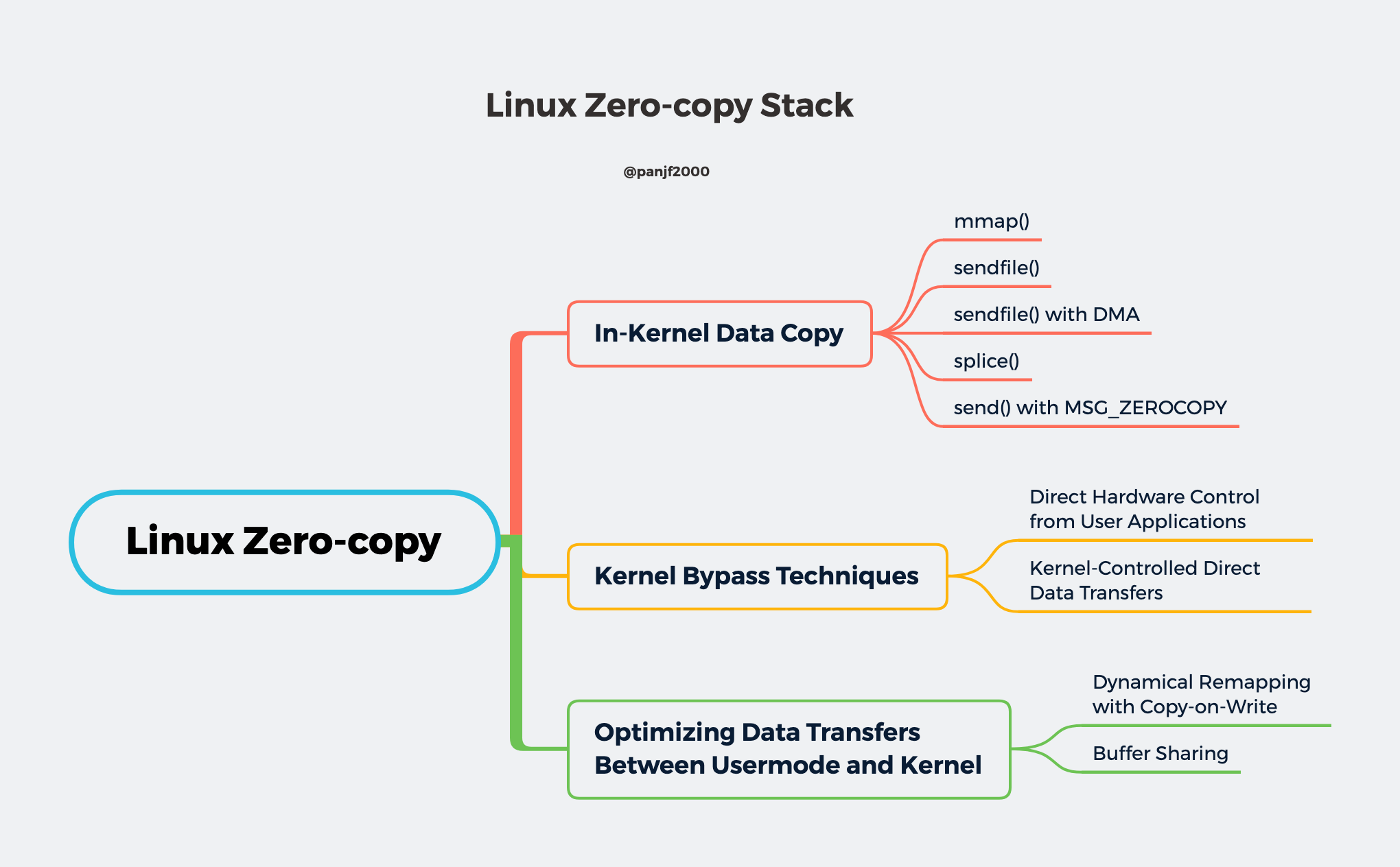
如今的网络应用早已从 CPU 密集型转向了 I/O 密集型,网络服务器大多是基于 C-S 模型,也即 客户端 - 服务端 模型,客户端需要和服务端进行大量的网络通信,这也决定了现代网络应用的性能瓶颈:I/O。 传统的 Linux 操作系统的标准 I/O 接口是基于数据拷贝操作的,即 I/O 操作会导致数据在操作系统内核地址空间的缓冲区和应用程序地址空间定义的缓冲区之间进行传输。设置缓冲区最大的好处是可以减少磁盘 I/O 的操作,如果所请求的数据已经存放在操作系统的高速缓冲存储器中,那么就不需要再进行实际的物理磁盘 I/O 操作;然而传统的 Linux I/O 在数据传输过程中的数据拷贝操作深度依赖 CPU,也就是说 I/O 过程需要 CPU 去执行数据拷贝的操作,因此导致了极大的系统开销,限制了操作系统有效进行数据传输操作的能力。 I/O 是决定网络服务器性能瓶颈的关键,而传统的 Linux I/O 机制又会导致大量的数据拷贝操作,损耗性能,所以我们亟需一种新的技术来解决数据大量拷贝的问题,这个答案就是零拷贝(Zero-copy)。
云原生 (Cloud Natvie) 是一种将应用程序以微服务的形式构建并使之运行在容器化和动态编排平台之上的方式,这些平台充分利用了云计算模型的优势。云原生关注的是应用如何构建和部署,而非运行在哪里。这些技术能够赋能组织/企业在公有云、私有云和混合云等现代和动态的开发环境里构建和运行可扩展的应用程序。这些应用程序是从头开始构建的,以松散耦合原则进行系统设计,并且专门针对云级别的规模和性能进行了优化,基于托管服务并利用持续交付来实现可靠性和更快的上市速度。总体目标是提高速度、可扩展性,以及最终提高利润率。

Strike Freedom
![]()
![]()


