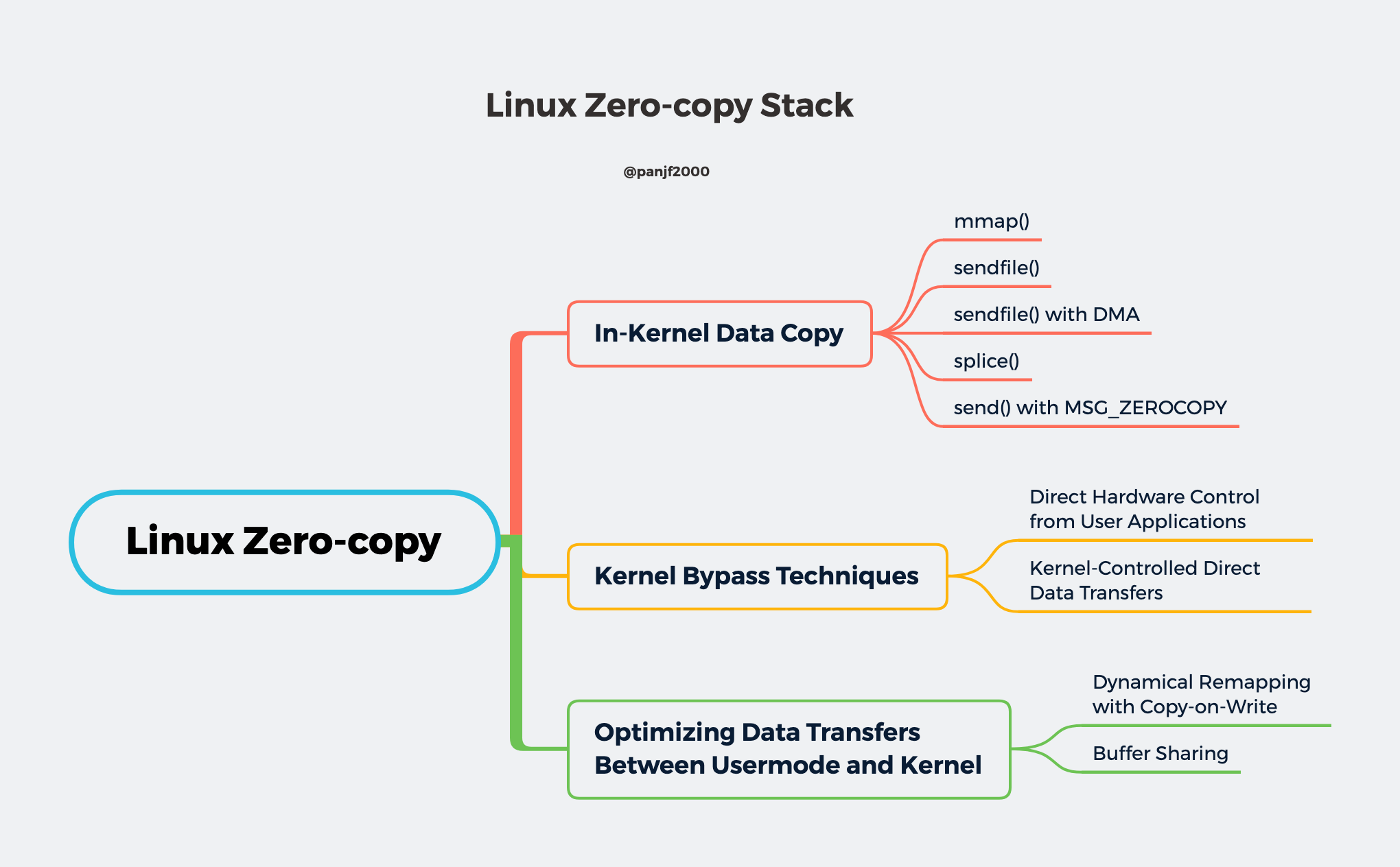
I/O,一直以来都是操作系统中核心中的核心,从我们进入互联网时代以后,全世界的互联网用户爆发式地增长,一批又一批的提供互联网服务的大型跨国公司不断地崛起,它们承载全是数十亿的网络流量,I/O 密集型的系统如网络服务器、数据库等逐渐占据了服务端领域,在海量的互联网用户面前,服务端的技术挑战不断涌现,网络服务器和数据库等系统的性能瓶颈愈发明显,而且大多数瓶颈都落在了 I/O 头上。Linux 作为有史以来应用最广泛的服务端操作系统,而且相较于 Windows 等闭源操作系统,Linux 开放了其内核的全部源代码,这三十余年以来,全世界有无数的开发者参与其中,对 Linux 内核进行优化和修复,因此 Linux 的底层 I/O 技术发展史基本就等同于人类同计算机 I/O 的抗争史。
本文将分为两大部分,第一部分会深入浅出地剖析整个 Linux I/O 栈,带领读者从用户空间出发,进入内核空间,直达底层物理硬件,让读者能深刻地理解整个 Linux I/O 栈的层次结构、底层实现以及历史发展;第二部分则是基于第一部分的知识,揭示了 Linux 是如何在传统 I/O 模式中走出来并且万丈高楼平地起,直至手摘星辰,对 I/O 进行深度的改造从而实现 Zero-copy I/O,这部分内容会全方位地揭秘 Zero-copy (零拷贝) 这项技术,以及它是如何在 Linux I/O 栈上大放异彩,并成为绝大部分服务端高性能 I/O 的基石。
全面而深入地剖析 Linux epoll 的 LT 和 ET 模式。
SO_REUSEADDR 和 SO_REUSEPORT 是 socket 编程中非常重要的两个套接字选项,同时也在实际的网络编程中经常会用到。从名字能够大概了解这两个选项的功能:前者是重用地址,后者是重用端口;概括一下就是,前者允许以相同的端口绑定不同的地址,后者允许以相同的地址再绑定相同的端口。
这两个套接字选项都是基于现实的网络编程问题而设计出来的,我会在本文中分析这两个选项实际解决的问题,能为网络编程带来哪些优势,其本身又有哪些劣势和副作用。最后我会再讲一讲这两个套接字选项在类 Unix 操作系统的不同平台上的实现有哪些异同,希望能为读者以后编写跨平台的可移植程序提供一点启发和参考。
今年初的时候我为 Go 语言实现了一个完整的 TCP Keep-Alives 机制。TCP keepalive 虽然是 TCP 协议标准却不是 POSIX 标准,然而用来支持 TCP keepalive 的三个套接字选项 `TCP_KEEPIDLE`、`TCP_KEEPINTVL` 和 `TCP_KEEPCNT` 却在类 Unix 操作系统和 Windows 上被广泛地支持,于是 Go 作为一个跨平台的编程语言,其 TCP keepalive 的支持必须尽量覆盖所有提供了这三个套接字选项的操作系统:Linux、macOS、Windows、*BSD (FreeBSD/DragonflyBSD/OpenBSD/NetBSD) 以及 SunOS (Solaris/illumos)。
期间我深入调研了一下 TCP keepalive 在这些不同平台上的具体实现的异同,以及踩过不少坑,在把这个功能提交到 Go 语言的代码仓库之后,算是对这方面熟稔了,后来我还给 redis、libevent、libuv 和 curl 等一众知名的开源项目都实现/补充了 TCP keepalive 机制,现在通过本文分享一下相关的经验,希望能对那些需要编写跨平台程序的读者有所帮助。
相对于 UDP 这样的无连接 (connection-less) 协议,TCP 是一种连接导向 (connection-oriented) 的可靠性协议,其目标是在不可靠的网络环境中实现可靠的数据传输。我们知道网络环境是复杂多变的,网络通信本质上是一种不可靠通信,要在不可靠的网络中实现 TCP 这样的可靠通信协议需要做很多工作:基于 TCP 协议的双端通信,在数据传输前需要建立一条连接,然后基于该连接来进行可靠的通信;在传输数据的过程中还要利用校验和、序列号、确认应答 (ACK)、重发控制、连接管理以及流量窗口控制等机制来实现可靠性传输;最后在终止连接的过程中也要处理一些异常情况以保证顺利关闭连接。
Introduction to ants Library ants implements a goroutine pool with fixed capacity, managing
受邀参加在 San Diego 举办的 Go Contributor Summit 2023 期间的所见所闻,和各路大神的交流心得,以及在 San Diego 的旅行记录。
受邀参加 Go Contributor Summit 2023,先行到旧金山和硅谷游览,期间所见所闻。
gogo-protobuf 即将寿终正寝,这是一个故事。
相信那些曾经使用 Go 写过 proxy server 的同学应该对 io.Copy()/io.CopyN()/io.CopyBuffer()/io.ReaderFrom 等接口和方法不陌生,它们是使用 Go 操作各类 I/O 进行数据传输经常需要使用到的 API,其中基于 TCP 协议的 socket 在使用上述接口和方法进行数据传输时利用到了 Linux 的零拷贝技术 sendfile 和 splice。 我前段时间为 Go 语言内部的 Linux splice 零拷贝技术做了一点优化:为 splice 实现了一个 pipe pool,复用管道,减少频繁创建和销毁 pipe buffers 所带来的系统开销,理论上来说能够大幅提升 Go 的 io 标准库中基于 splice 零拷贝实现的 API 的性能。因此,我想从这个优化工作出发,分享一些我个人对多线程编程中的一些不成熟的优化思路。