
Mac 开发系列之 python 多版本和环境管理(pyenv和virtualenv安装配置使用)
系统版本:Mac OS X El Capitan(10.13) 预先安装:homebrew 安装方法:运行ruby脚本: 1 pyenv依赖:python 2.5+ , git pyenv安装 推荐使用pyenv-installer这个插件安装pyenv,这种方式安装会多安装几个是实用的插件,比如: 1 1
系统版本:Mac OS X El Capitan(10.13) 预先安装:homebrew 安装方法:运行ruby脚本: 1 pyenv依赖:python 2.5+ , git pyenv安装 推荐使用pyenv-installer这个插件安装pyenv,这种方式安装会多安装几个是实用的插件,比如: 1 1
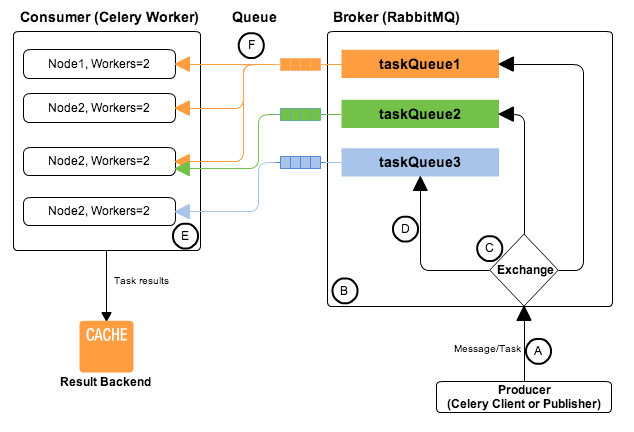
Tornado和Celery介绍 1.Tornado Tornado是一个用python编写的一个强大的、可扩展的异步HTTP服务器,同时也是一个web开发框架。tornado是一个非阻塞式web服务器,其速度相当快。得利于其非阻塞的方式和对 epoll的运用,tornado每秒可以处理数以千计的连接,这意味着对于实时web服务来说,tornado是一个理想的web框架。它在处理严峻的网络流量时表现得足够强健,但却在创建和编写时有着足够的轻量级,并能够被用在大量的应用和工具中。 进一步了解和学习tornado可移步:tornado官方文档 2.Celery Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,它是一个专注于实时处理的任务队列, 同时也支持任务调度。Celery 中有两个比较关键的概念: Worker: worker 是一个独立的进程,它持续监视队列中是否有需要处理的任务; Broker: broker 也被称为中间人或者协调者,br
Strike Freedom
![]()
![]()
![]()
![]()